(一)简介:
正则表达式,又称为正规表示式,规则表达式等,英文为Regular Expression,在代码中常写为regex。正则表达式使用单个字符串来描述,匹配一系列满足某个句法规则的字符串。
(二)Re模块操作:
- 1.re模块的使用过程:
#导入re模块import re#使用match方法进行匹配操作result = re.match(正则表达式,要匹配的字符)#如果上一步匹配到数据后,可以使用group方法来提取数据result.group()
re.match 是用来进行正则匹配的方法,如若字符串匹配正则表达式,则match方法返回匹配对象(Match Object),否则返回None(注意不是空字符串 “ ”)。
匹配对象Match Object具有group方法,用来返回字符串的匹配部分
- 2.re示例:
1 import re 2 3 #匹配模式 4 pattern = 'itcast' 5 #带匹配串 6 s1 = 'itheima' 7 s2 = 'itcast' 8 9 #匹配10 result = re.match(pattern,s2)11 12 print(result)13 print(result.group())14 15 16 》》》输出:1718 itcast
说明:
- 如果上述代码中匹配的是s2,那么将输出None,并且也没有group()。
- match()能够匹配的准确来说是以pattern开头的字符串,也就是说,尽管我们待匹配的项中可能还含有其他字符,但是只要从头开始完整匹配到模式pattern就会返回满足匹配模式的匹配对象,下列举例说明。
1 import re 2 3 #匹配模式 4 pattern = 'it' 5 #带匹配串 6 s1 = 'itheima' 7 s2 = 'itcast' 8 9 #匹配10 result = re.match(pattern,s1)11 12 print(result)13 print(result.group())14 15 16 》》》输出:1718 it
(三)表示字符
上述我们介绍了最简单最基本的匹配过程作为一个引入,接下来我们定义一些具有通用性的规则,而不是只针对我们提前写好的匹配模式。
. (这是一个点) ——匹配任意1个字符,\n除外。
\d ——匹配数字,即0--9 ,(以digit助记)
\D ——匹配非数字,即不是数字的。
\s ——匹配空白字符(在这个地方没有显示出任何有实际意义的东西),如\n,\t,\r
\S ——匹配非空白
\w ——匹配单词字符,即a-z,0-9,A-Z,_(下划线)(word单词助记,何为单词,即我们在py中能参与命名的东西)
\W ——匹配非单词字符
示例1:
>>> import re>>> ret = re.match('.', 'abc')>>> ret.group()'a'>>> ret = re.match('\d', '123A')>>> ret.group()'1'>>> ret = re.match('\s', '\n')>>> ret.group()'\n'>>> ret = re.match('\W', '-')>>> ret.group()'-'
上述符号都只能匹配1类满足的字符,那如果某个待匹配字符满足满足多个性质,比如三位待匹配字符串,而第二位 是1也可以,是所有的字母也可以,那怎么办呢?
就要用到下列这个字符模式!
[ ] ——匹配[ ]中列举的字符
>>> re.match('.[1a-zA-Z]', '914') >>> re.match('[^123]', 'A')
上述中在[]内只需把要匹配的模式并排着写就可以了,不需要空格,
然后^表示取反的意思,就是非XXX。
由此我们发现似乎[]可以代替其他许多字符欸,答案还真是,请看如下等价转换:
\d = [0-9]\D = [^0-9]\w = [a-zA-Z0-9]\W = [^a-zA-Z0-9]
(四)表示数量
如果现在有一个实例是我们需要匹配用户输入的手机号是否满足规则:第一位是1,第二位是偶数,第三位到第九位是数字,按照上面所学我们能完成,但第三位到第九位的匹配会不会太复杂了,有没有什么办法能简化呢,因此接下来的字符就是表示数量的含义!
* ——匹配前一个字符出现0次或者无限次,即可有可无
+ ——匹配前一个字符至少出现1次
? ——匹配前一个字符出现1次或者0次,即要么1次,要么0次
这三个字符我们举一些例子:
1 >>> re.match('\d*','123')2 3 >>> re.match('\d*', 'ABC')4 5 >>> re.match('\d+', 'A12') #没有输出表示None,即没有匹配到相应字符6 >>> re.match('\d?','ABC')7 8 >>> re.match('\d?', '123')9
这是可能有同学有疑惑了,第8行的?表示的明明是匹配数字出现1次或0次,这里明明出现了三个字符啊?先不要着急我们看下面这个例子:
>>> re.match('\d?[a-z]', '123aBc')>>>
为什么上述又是None了呢,对比上述两个匹配代码相信有想法了吧!
原因就是
当我们只有 \d?时表示匹配数字1次或者0次,我们就看待匹配第一个字符满足与否,如果第一个是数字,那么就匹配成功了,返回对象就是该字符,如例子所示;如果不是数字,则自然表示为空。
当我们是 \d?[a-z] 时,根据我们所举例子表示从1位是数字满足,但由于?只匹配一次数字,所以第二位就应该根据[a-z]来进行匹配发现错误,所以没有找到满足匹配模式的匹配对象,返回为空。
那如何具体表示我要匹配多少次呢,就要用到如下符号:
{m} ——匹配前一个字符出现m次
{m,} (注意m后面多了一个逗号) ——匹配前一个字符至少出现m次
{m, n} ——匹配前一个字符出现从m到n次
For example:
>>> re.match('\d{3,}[a-z]', '123abc') >>> re.match('\d{3,5}[a-zA-Z]', '1234abc')
到这里我们先刹刹车,大家看下面代码,有没有发现什么问题:
1 >>> re.match('\d*', 'a')2 3 >>> re.match('\d?', 'a')4 5 >>> re.match('\d', 'a')6 >>> 7 >>> re.match('\d*a', 'a')8
我们说在没有输出表示为None,而1,3行代码有输出啊,只不过是‘’罢了,为什么呢?
其实只需想象在 ‘a’ 的a之前有一个‘’(空字符位)即可,这样问题不是就解决了,而第7行的代码也就能解释了!
(五)原始字符串
我们知道在C或者Python中有转义字符的存在,也就是 \n 表示换行,而我们如果确实就想要 \n 呢?
我们的处理办法通常是 \\ 表示 \ :
>>> s = '\nabc'>>> s'\nabc'>>> print(s) #这个空行表示的就是\nabc>>> s = '\\nabc'>>> s'\\nabc'>>> print(s)\nabc
所以在Python中 :字符串前面加上 r 表示原生字符串,这在文件操作中打开一个windows下的文件也有用的哦!
1 >>> s = r'\abc'2 >>> print(s)3 \abc4 >>> file_name = "c:\\a\\b\\c"5 >>> ret = re.match(r'c:\\a', file_name)6 >>> print(ret.group())7 c:\a
(六)表示边界
上面所列几类基本能完成一定的操作,但是如何进行边界的确定呢,请看下列字符:
^ ——匹配字符串开头
$ ——匹配字符串结尾
\b ——匹配一个单词的边界
示例如下:
1 >>> re.match('^1[246]\d{7}$', '141111111')2 3 >>> re.match(r'^\w+me\b', 'home')4 5 >>> re.match(r'\w+\s\bve\b', 'ho ve r')6 7 >>> re.match(r'^.+ve\B', 'hover')8
(七)匹配分组
接下来,我们进一步思考,如果此时我们要匹配0--100中的任何数呢,也就是说只要这个数在0-100之间,我们就应该匹配出来?
首先我们排除掉100和0两种极端情况我想应该很好写吧,就是:
re.match(r'[1-9]\d$', '29')
接下来如何把100和0也包含进去呢,就用到接下来我们讲的一组符号了。
| ——匹配左右任意一个表达式
(ab) ——将括号中字符作为一个分组
\num ——引用分组num匹配到的字符串
(?P<name>) ——分组起别名
(?P=name) ——引用别名为name分组匹配到的字符串
接下来我们具体来解释每一个的意义:
| :
继续引出中的例子,匹配0-100的数字
1 >>> re.match(r'[1-9]\d$|100$|0$', '78')23 >>> re.match(r'[1-9]\d$|100$|0$', '100')4 5 >>> re.match(r'[1-9]\d$|100$|0$', '0')6
(ab):
当我们在爬虫时,在解析网页这一步骤当中,我们会大量匹配 <h1>XXX</h1> 这种类似标签中的信息,这是就要用到分组模式:
>>> ret = re.match(r'(.*)
', '匹配分组
')>>> ret.groups()('匹配分组',)>>> ret = re.match(r'().*(
)', '匹配分组
')>>> ret.groups()('', '
')
括号内为一个整体,用groups()输出时,会以元组的方式返回各个括号内的匹配内容
再举一个例子,我们把前两种综合使用,想提取邮箱账户怎么办:
1 #比如XXX@qq.com XXX@163.com XXX@162.com 2 s = 'Boru123456@163.com' 3 p = r'(\w+)@(qq|163|162)\.com$' 4 ret = re.match(p, s) 5 print(ret.group(1)) 6 print(ret.group(2)) 7 print(ret.groups()) 8 9 10 》》》输出:11 Boru12345612 16313 ('Boru123456', '163')
\num:
一般与()结合使用,以完成在匹配模式中再次定义匹配,什么意思,看下列代码:
需要匹配出:<html><h1>www.itcast</h1></html>
import re#正常匹配情况ret = re.match(r'<.+><.+>(.*) ', 'www.itcast
')print(ret.groups())#但是如果这样,假如前后标签不匹配的情况下,我们也会把中间的东西匹配出来,#这显然不是我们想要的,所以经过观察,如果是正常的HTML标签,其格式一定时固定的。ret1 = re.match(r'<(.+)><(.+)>(.*) ', 'www.itcast
')print(ret1.groups())》》》输出:('www.itcast',)('html', 'h1', 'www.itcast')
(?P<name>),(?P=name):
那如果上面那个匹配标签的代码有20个括号呢,也就是说当我们可能无法记清楚是第几个的时候我们可以给我们定义的标签标注名字,以便在后面的使用中避免混淆,举个例子就清楚了:
1 ret1 = re.match(r'<(?P.+)><(?P .+)>.* ', ' www.itcast
')2 print(ret1.groups())3 4 5 》》》输出:6 ('html', 'h1')
其中 定义格式为 ?P<标识> 使用格式为 ?P=标识,一般混合使用。
(八)re模块高级用法
- search:从左往右匹配第一个满足条件的匹配对象并返回
ret = re.search(r'\d+', '阅读次数为999')print(ret.group())》》》输出:999
假如此时需要统计py,C,C++相应文章的阅读次数就需要findall
- findall:以列表的形式返回所有匹配对象
ret = re.findall(r'\d+', 'python阅读次数为999,C++为99,C为9')print(ret)》》》输出:['999', '99', '9']
接下来,我觉得py很腻害我想把他的阅读次数改成10000,怎么办,这时候就需要sub
- sub:将匹配到的对象内容更改为自定内容
ret = re.sub(r'\d{3}', '10000', 'python阅读次数为999,C++为99,C为9')print(ret)》》》输出:python阅读次数为10000,C++为99,C为9
可是这样的话,学习C或C++的同学可能就不满意了,所以我们不能单独只给python加,他们三个我都要在原来的基数上加上100,那怎么办呢?
答案就是除了简单的替换外,自定内容还可以是一个函数:
1 def replace(result): 2 r = int(result.group()) + 50 3 return str(r) 4 5 ret = re.sub(r'\d+', replace, 'python阅读次数为999,C++为99,C为9') 6 print(ret) 7 8 9 》》》输出:10 python阅读次数为1049,C++为149,C为59
现在,我又想把他们都分隔开形成一个列表又怎么办呢,不慌,还有split
- split:根据匹配进行切割字符串,并返回一个列表。
ret = re.split(r',|;| ', 'python阅读次数为999,C++为99;C为9 还有一个Pascal为0')print(ret)》》》输出:['python阅读次数为999', 'C++为99', 'C为9', '还有一个Pascal为0']
最后,还有最后一个了, 胜利的曙光就在眼前了。
(九)贪婪与非贪婪:
我们看如下一个例子:
1 s = 'This is a number 234-34-45234-454' 2 #我想匹配s中的数字怎么办?我们理想思路应该如下: 3 r = re.match('.+(\d+-\d+-\d+-\d+)', s) 4 5 #接下来输出括号的元素就可以啦 6 print(r.group(1)) 7 8 9 》》》输出:10 4-34-45234-454
为什么会不对呢?按道理来说,当我 .+ 匹配到2前面时就自动停止啦,然后后面的数字归 \d 匹配了啊,问题就在py默认匹配是贪婪模式,也就是尽可能要吃饱,我们第一个 \d+ 表示至少匹配一个数字,所以他只需要给一个4让 \d+ 匹配就好咯,因此前面的 .+ 就会贪婪的多匹配两个数字!
那怎么解决呢,其实非常简单,只需在原来的基础上加上一个 ? 即可,如下:
1 s = 'This is a number 234-34-45234-454' 2 #我想匹配s中的数字怎么办?我们理想思路应该如下: 3 r = re.match('.+?(\d+-\d+-\d+-\d+)', s) 4 5 #接下来输出括号的元素就可以啦 6 print(r.group(1)) 7 8 9 》》》输出:10 234-34-45234-454
我们再来分析一下如下例子:
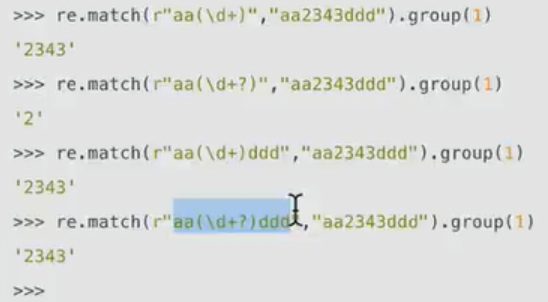
第一个很好理解,第二个关掉贪婪模式,尽可能少的匹配。
第三个很好理解,第四个就要注意了,虽然此时关掉了贪婪模式,但是在左右匹配都完成的情况下,留给中间部分的就只有2343了 不存在贪不贪婪的问题了!
所以贪婪与非贪婪不是绝对的,要根据具体情况而言!
OK,这就是正则表达式的相关内容了,后续再见!